
Anthropic and OpenAI just validated the problem WALT was built to solve
.webp)
Two of the world's most advanced AI teams published how they built their internal data agents. Their conclusions read like WALT's design docs, and they show why solving this at enterprise scale takes an autonomous data engineer, not another warehouse.
Within a few weeks of each other, Anthropic and OpenAI each published a detailed account of how they built an internal AI data agent. Anthropic's data team explained how they automate 95% of business analytics queries at ~95% accuracy. OpenAI's walked through the agent that lets 3,500 employees query 600 petabytes across 70,000 datasets in natural language.
Reading them back to back felt like reading our own design docs.
Out of every approach the industry has floated for self-service analytics, these are the two that actually understand the gravity of the problem. They don't treat text-to-SQL as a clever demo. They treat it as a context-and-verification problem that has to be engineered, governed, and defended against decay. That is exactly the thesis WALT was built on. So rather than rebut these posts, we want to do something more useful: map them, point by point, to what we already ship, then name what their playbooks leave on the table for the enterprises we serve.
The thesis they confirmed: data is not software
Anthropic put it plainly: "pointing Claude at a warehouse and letting the agents execute can create a false sense of precision." They go on to argue that analytics accuracy is "a context and verification problem, not a code generation issue," because coding has tests and documentation as natural guardrails while analytics often has "only a single correct answer using a single correct source in which there's no deterministic way of proving the correctness."
We've been saying a version of this since day one. An LLM is stochastic by construction: even at temperature zero, a transformer samples from a probability distribution. That's wonderful for open-ended creativity and disqualifying for production reporting, where an answer that drifts from one run to the next is simply wrong. The entire premise of WALT's neuro-symbolic architecture is that you let the neural model do what it's good at (understanding intent, resolving ambiguity) and hand correctness, consistency, and auditability to a deterministic symbolic engine. We agree.
Where the playbooks line up with ours, point for point
Read the two posts closely and the same handful of ideas keep surfacing, the same ones that define ReasonBase, our Data Context Graph, and our Stable Logic Models.
Mapping the question to the right entity is the whole game. Anthropic: the central problem is "our ability to map a user's question to specific and up-to-date entities in our data model… If we can do that, then the resulting execution and SQL becomes trivial." That sentence is the Reasoner. The hard part was never the SQL; it's resolving "weekly active users" to a governed entity. Our ontology and knowledge graph exist to do precisely that.
Concept-to-entity ambiguity is the dominant failure. Both teams describe the "forty plausible revenue tables" problem. We describe it as revenue, revenue_final, revenue_corrected. Which one is right? Canonicalizing business vocabulary onto trusted data assets is the founding job of the Data Context Graph.
Humans own definitions; the model drafts them. Anthropic tried bootstrapping their semantic layer by having an LLM auto-generate metric definitions and found it "produced plausible-looking definitions that encoded the very ambiguities we were trying to eliminate." Their conclusion: generate documentation with Claude, but have a human own the definition. That is our "human-in-the-loop on intent" principle verbatim: humans decide what data should mean; agents handle implementation.
Reusable analytical patterns beat reinventing each query. Anthropic's skills bundle "retention curves, rate decomposition, funnel analysis." Those are our Logic Models: time-over-time comparisons, cohort analysis, fanout-protected joins, multigrain models. The difference is that ours aren't prompts the model interprets; they're deterministic structures the AST compiler builds SQL from.
The query corpus is raw material, not a source of truth. This is the most striking convergence. Anthropic gave their agent grep access to thousands of prior SQL files and accuracy moved "by less than a point." The information was present, the agent read it, and it still didn't use it correctly. Their takeaway: the bottleneck wasn't access to prior work, it was structure. This is the quiet death of the question-SQL-pair approach that most of the market is selling. RAG over a pile of past queries does not scale, because mapping a new question to the right precedent is the unsolved part. We went a step further than either lab: we don't ask the LLM to write SQL at all. Less generation means fewer tokens, less hallucination, lower cost, higher speed, and higher accuracy.
Metadata is a first-class, versioned product that lives inside the estate. Anthropic's hardest-won lesson is that metadata has to be treated "as a first-class product" and colocated with the models, so the PR that changes a model is the PR that updates the doc, enforced by CI. We took that idea to its logical end. In a WALT-authored data platform, every member of the data estate emits its own semantics and lineage. Governance and semantics are not a system bolted on the outside; they are part of the estate itself. And we treat every mutation of the context graph as a git revision, automatically running our eval suite on the change. Colocation isn't a discipline a human has to remember; it's how the platform is built.
Staleness is an engineering problem, not an afterthought. Anthropic watched offline accuracy drift from ~95% to ~65% in a month before they treated documentation decay as engineering work: colocating skill files with models and adding CI hooks. OpenAI rebuilds context daily and auto-refreshes code-derived enrichment. Our Operator and self-evolving design treat schema change, source drift, and definitional evolution as normal operations, not exceptions.
Verification is harder than a string match, and we built for that. Both labs landed on evals as the only way to ship without breaking trust: Anthropic pins every eval to a snapshot date; OpenAI explicitly rejects "naive string matching" because correct SQL can differ syntactically and return extra columns. We agree, and we go further. Our evals run against snapshotted data and score on F1, because an agent gives you no guarantee it returns the exact same set of columns every time, and the rows and columns won't come back in the same order either. A serious eval module has to be robust to all of that: set-based, order-independent, and tolerant of acceptable variation while still catching real regressions. That sophistication is not optional once the answer feeds a decision.
The tell: look how much blocking and tackling it took
Here's what should give every data leader pause. These are two of the most talented engineering organizations on earth, working on comparatively clean, modern, homogeneous data estates that they themselves built. And it still took both of them an enormous amount of scaffolding to get to production:
- skills frameworks, colocated repos, and CI gates
- mandatory-semantic-layer routing
- adversarial review sub-agents (Anthropic reports +6% accuracy at +32% tokens and +72% latency)
- six layers of context engineering, embeddings pipelines, and memory systems
- eval suites pinned to snapshot dates
- provenance footers to flag the silent-wrong-answer case they admit they haven't fully solved
If that's the cost of reliable analytics agents on a clean estate with world-class talent, the obvious question is: what happens to everyone else?
What their playbooks leave on the table
Both labs start at the warehouse. The enterprise problem starts at the source. Anthropic and OpenAI's agents reason over a warehouse that already exists: clean, modeled, governed, and built by the same teams now writing the agent. That's the luxury at the root of everything else. WALT's Ingestor goes all the way back to the source systems, discovering sources, negotiating contracts, and landing data from the operational systems where the real mess lives: nested JSON, dates as varchars, inconsistent nulls, no shared vocabulary across SaaS tools, and PII interleaved into operational records. The path from a Starbucks card-tap to a trustworthy "how many lattes did we sell" answer is never one hop, and in a real enterprise nobody has done those hops for you.
"Just build canonical datasets" is the hard part, not the starting point. Both posts assume you can curate a small set of governed, single-source-of-truth datasets and deprecate the duplicates. In large enterprises (fragmented systems, stored procedures, flat files, mergers layered on mergers), that curation is the whole problem. It's the project that's been stalled for a decade. This is exactly why WALT took on full autonomous data engineering: the Ingestor, Transformer, and Reasoner build the medallion and shape the Gold layer from real consumption patterns, on whatever topology you already have, on-prem or cloud, legacy or modern. We don't require you to have solved canonicalization before the agent is useful. Building the canonical layer is the work the agent does.
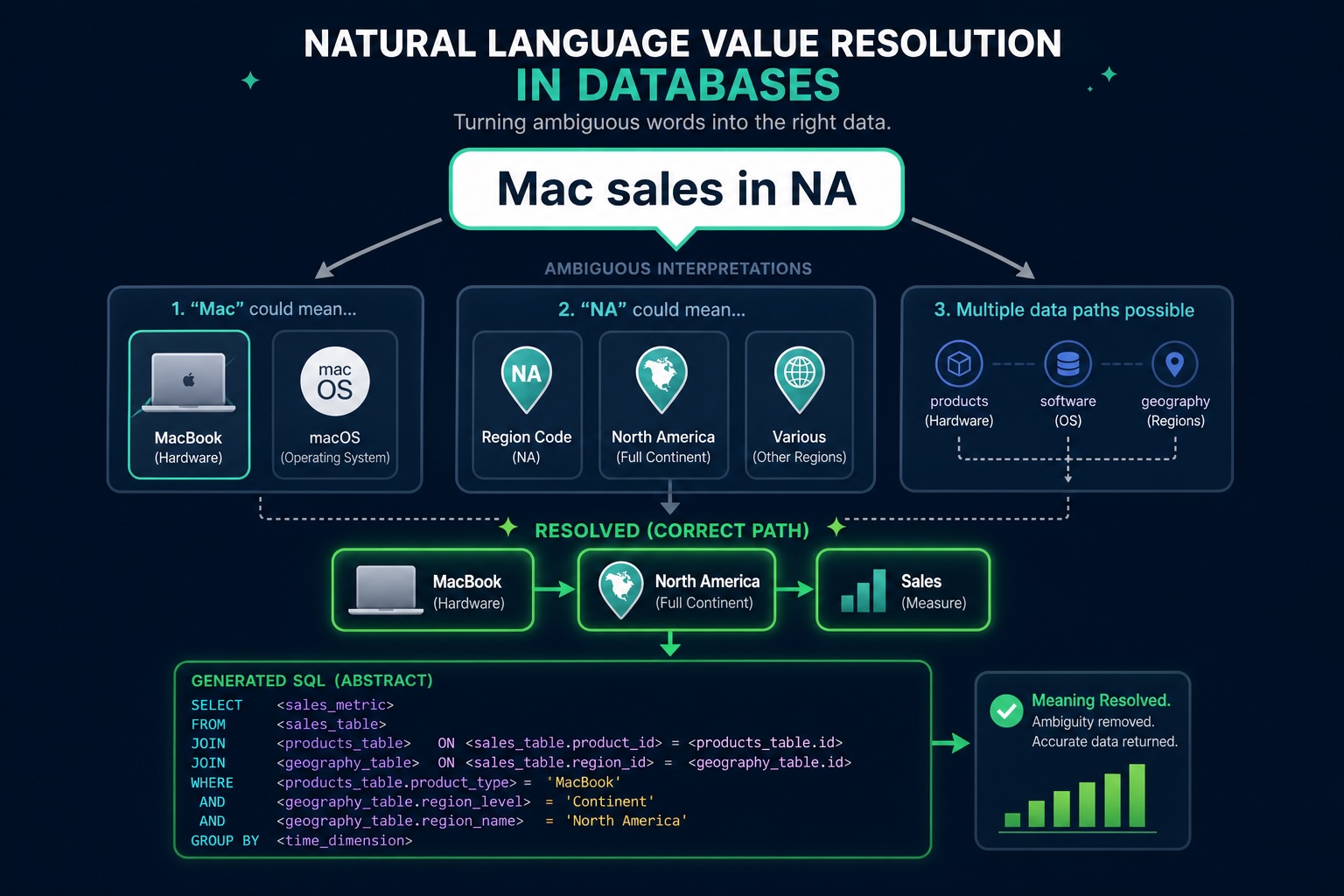
Users ask for data by its values, not by its metadata. Neither post addresses the question a real business user actually types: "How are Mac sales in NA?" "Mac" isn't a table name or a column. It's a value, and it's ambiguous in the data itself: macOS or MacBook Air? Both sides of the WHERE clause are unknown: you don't know which column the value lives in, and you don't know how it's stored ("North America," "NA," a region code). An LLM guessing here returns empty results or, worse, wrong data that looks right. WALT solves this neuro-symbolically: we detect low-cardinality attributes, vectorize every distinct value, and build a semantic index, so "Mac" resolves to the actual value in the actual column before a single clause of SQL is composed. Metadata grounding, where both labs stop, doesn't touch this. It's the gap between a demo and a tool a non-technical user can trust.
The estate should get smaller, not bigger. The big-data era told everyone to capture everything, and data estates sprawled while the bills for storage and compute climbed every year. We're seeing the opposite truth: less is more. Because WALT builds the canonical layer from actual consumption, the agents can prune the estate down to what's used and stop paying to maintain the rest. Our Operator even materializes and dematerializes canonical models based on usage; a model that nobody queries doesn't need to sit there accruing cost. Neither lab post grapples with the bill; for the enterprises we serve, shrinking the estate is often the fastest ROI in the whole project.
The same level of thinking, pointed at a different world
Two of the most sophisticated AI teams on earth independently arrived at our thesis: collapse ambiguity into one governed answer, make it discoverable, flag it when it goes stale, and never mistake the model's fluency for correctness. We read these posts as peers. The architecture is no longer in question. The two best labs in the world just confirmed it.
It's worth noting how far this has moved from the last era of data platforms, which sold the opposite premise: centralize everything, lift and shift into one more platform, then hire a team to model it by hand. That worldview produced sprawling estates, rising bills, and a canonical layer that was perpetually one migration away. The new thesis is that meaning and verification, not storage and compute, are the hard part.
The enterprise reality is a long tail:
- Every industry encodes its own meaning of "active," "revenue," "customer," and "region."
- Every decades-old company has its own idiosyncratic history baked into the data.
- There is no single canonical layer to ship. There are tens of thousands of them, one per enterprise.
Each one demands the same work redone against a different mess: source-to-Gold modeling, value resolution, governance, and evals. That is not a feature anyone ships next quarter. It is a large, ongoing undertaking that has to be solved for every enterprise, one at a time, and it calls for a structurally different model: agents doing the labor that used to take a data team a year, delivered as something closer to service-as-software than a seat license.
WALT is the autonomous data engineer for that world: the fragmented, decades-old, mission-critical estates where the canonical dataset doesn't exist yet and the CFO still needs the same answer twice. That's the problem. We're glad the best in the world agree it's the right one.
Sources
- Anthropic, "How Anthropic enables self-service data analytics with Claude"
- OpenAI, "Inside OpenAI's in-house data agent"


Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)