
Data Ingestion in the Agent Era: Orchestrate, Don’t Reinvent
.webp)
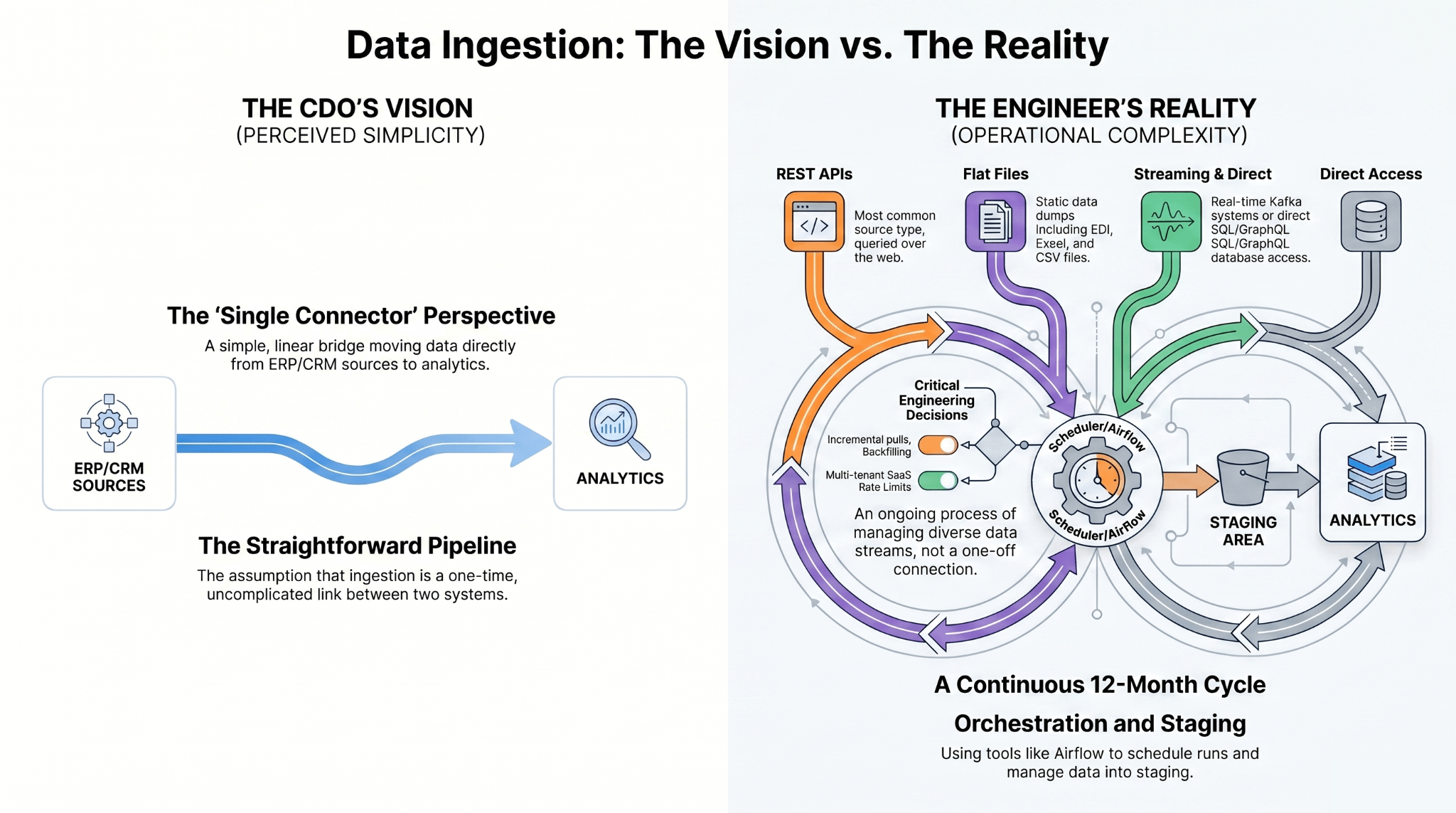
Hand a chief data officer an "ingestion project" and they picture one thing: an engineer writing a connector. Hand that same project to an engineer who has actually run ingestion in production, and they picture the next twelve months of their life.
That gap between the two mental models is where almost every ingestion budget overrun is born. The connector is the part everyone can see, but the work that quietly eats time and money is everything wrapped around it.
This piece is about orchestrating everything around the connector, and about what changes when an autonomous agent takes it over.
What is ingestion? How does it work?
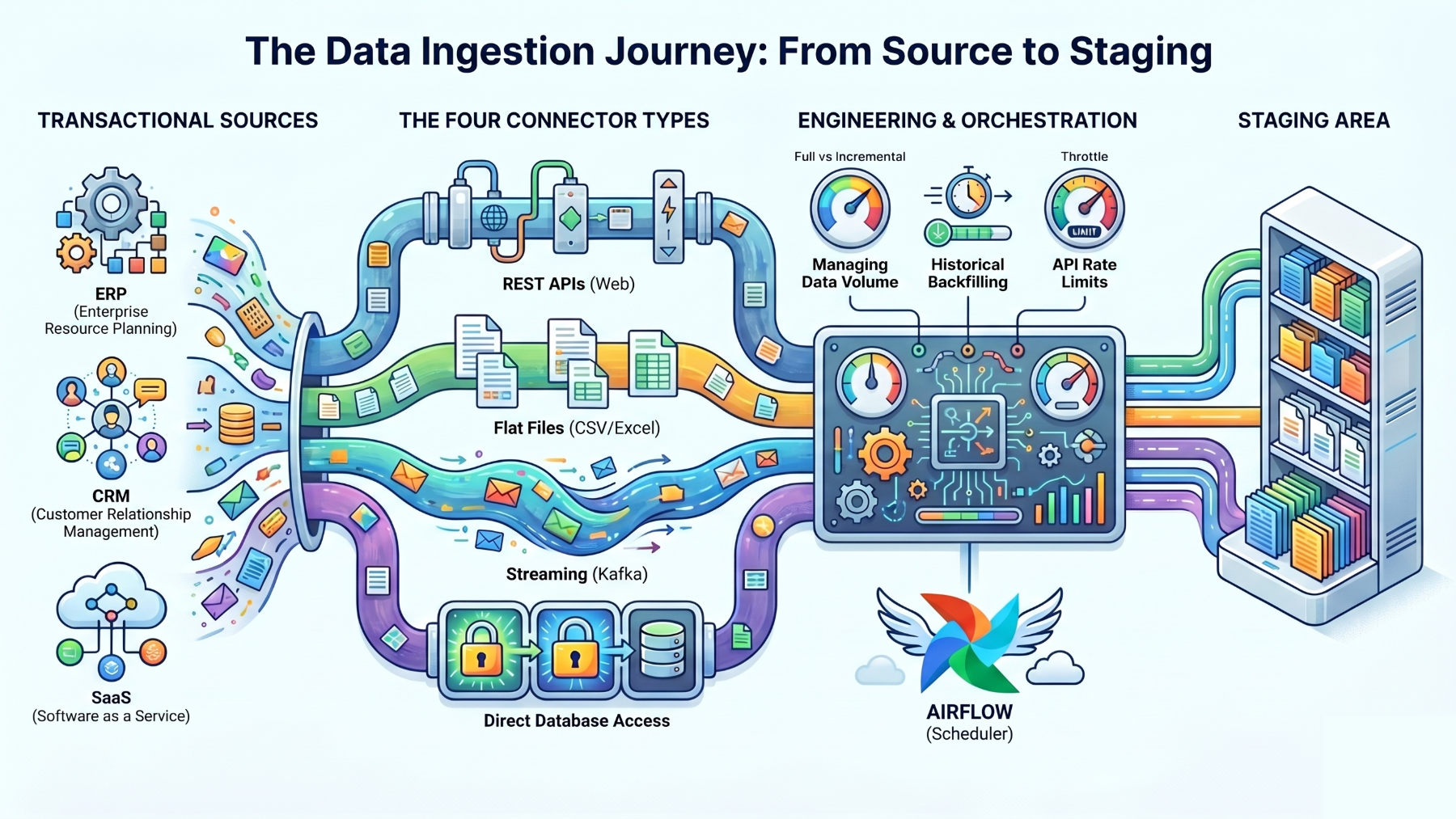
Ingestion is the process of pulling data from a transactional source (an ERP, an order-processing system, a CRM, a SaaS app) into a centralized place where analytics can use it. Connectors are the pieces that talk to each source and move the rows.
Connectors come in four basic flavors:
- REST APIs: the most common source type, queried over the web.
- Flat files: EDI, Excel, and CSV dumps.
- Streaming systems: Kafka and the tools that sit around it.
- Direct database access: Pulling straight from a source over SQL or GraphQL.
On top of the connectors, an engineer still has to decide:
1. How much data to pull each run–the full dataset every time or only the records that changed since the last run;
2. How to backfill history without taking production down;
3. (For multi-tenant SaaS sources) How to stay inside rate limits without starving other tenants.
After that, a scheduler like Airflow decides when each connector runs and in what order, runs the whole thing on a cadence, and drops the data into a staging area.
Where the pipeline breaks: Seven common reliability problems explained
Building the connector and scheduling it is the part you do once. Keeping it alive is the part you do forever. 97% of senior data leaders surveyed by Fivetran cite broken pipelines as the reason for slower analytics and AI initiatives, costing around $3 million in average monthly business exposure.
Seven failure modes drive most of that ongoing work, and none of them are exotic. Every one is a normal Tuesday for an ingestion engineer.
1. Pagination: Most APIs hand back one slice of the data per call. You have to walk every page without losing rows or counting them twice.
2. Retries: Networks fail mid-run. You need to retry safely, so a single transaction never lands twice.
3. Schema drift: The source quietly adds, renames, or drops a column. Your pipeline does not notice until something downstream breaks.
4. Rate limits: The source allows 100 calls a minute. Your job tries 1,000 and gets locked out.
5. Incremental cursors: Remembering exactly where you stopped last time. Simple in theory, and full of small ways to get it wrong.
6. Auth refresh: Tokens expire. If your pipeline cannot refresh them cleanly, it just stops at 3am.
7. Connector maintenance: The source changes its API. Every connector you didn’t write has to be patched by somebody, and that somebody is usually your data engineer.Fivetran also found that on average, enterprises face almost 5 pipeline failures each month, and these incidents take nearly 13 hours to resolve.
And yet the connector is already a commodity
Those seven problems look like a connector problem. If they were, the fix would be easy: buy a better connector.
You can. Airbyte, Fivetran, Lakeflow Connect, BigQuery Data Transfer, Azure Data Factory all move rows from A to B competently, with retry logic, pagination, and rate-limit handling already built in. Scheduling is a commodity too, thanks to Airflow and everything that grew out of it.
A CDO who still treats ingestion as a build-versus-buy connector decision is fighting last decade's war. The connector is settled.
Data engineering teams are still underwater because commoditizing the connector wasn’t the fix. The problem lies with operating the connector, and operation is the part no tool solves.
So where does human time actually go?
We’ve established building/buying the connector isn’t the problem. Instead, it’s the engineering time and effort that goes into every task surrounding the connector:
- Scoping: Figuring out which systems and APIs even matter for the question being asked.
- Access: Setting up authentication, service accounts, scopes, and network paths.
- Sync strategy: Choosing the right incremental approach per source, then revisiting it when the source changes.
- Shaping: Flattening nested JSON into something analytics can actually read.
- Debugging: Chasing failed syncs at unsociable hours.
- Orchestration: Sequencing dependencies, retries, and backfills without breaking production.
- Monitoring: Watching freshness and completeness so you notice when a feed dies.
Here’s a realistic estimate for a mid-sized enterprise, based on what we see in the field: a competent ingestion engineer takes two to six weeks to stand up a single new source end to end, then spends 30-60% of their time operating, debugging, and patching what they built.
That field estimate is not an outlier. The Fivetran survey cited earlier also found that 53% of data engineering capacity is devoted to maintaining and troubleshooting pipelines. A large chunk of that time also goes into rebuilding pipelines after deployment, often because an API changed under them. Now multiply that by hundreds of sources, and that’s the headcount problem every CDO already knows.
The structural truth: Connectors are cheap, operations are expensive
The unit economics of ingestion have inverted from where most CDOs first learned them. Twenty years ago the connector was the cost. It was genuinely hard to build, so you paid skilled engineers to build it.
Today the connector is free or close to it, and the operation around it is the expensive part. Most ingestion budgets are still written as if it were 2008: plenty for the build, almost nothing for the years of operating that follow.
What does an ingestion agent do?
If operation is the cost, then operation is what an agent has to take over. An ingestion agent runs the wrapping.
An ingestion agent is an autonomous data engineer that orchestrates the work around a data connector, escalating only the decisions that need human judgment.
The ingestion agent discovers what sources exist, profiles their schemas, and proposes an incremental strategy for each one. It schedules the runs, watches every sync, and raises a ticket the moment a feed drifts. When a schema changes, it files the downstream fix as a proposal, rather than letting the change break a dashboard three steps away.
This autonomous data engineering agent takes over the grunt work: the 3 AM page, the JSON flattening, and the hundredth rate-limit tweak, and only escalates when the decision actually requires human judgment.
How do you build ingestion agents that are trustworthy? Orchestrate, don’t reinvent.
Knowing what the autonomous ingestion agent does is not the same as knowing how to build one you can trust. Get the architecture wrong and you have just automated the chaos.
Start with one rule: an ingestion agent should not arrive as one more connector platform you have to buy, approve, and rip out in three years. Instead, this agent should work through commodity ingestion tools (Airbyte, Fivetran, Lakeflow Connect, the cloud-provider equivalents), and don’t replace them. An autonomous ingestion agent merely recommends, configures, operates, and integrates your existing tools.
Since those vendors also ship agentic interfaces, the ingestion agent will lean on agent-to-agent (A2A) communication to delegate each tool the job it does best. For a 2026 data platform, that is the honest posture: orchestrate proven ingestion tooling, don't rebuild it.
A note on technique: Opt for neuro-symbolic, and not single LLM
A tempting solution is to point one large language model at the whole problem and let it sort ingestion out. But that’s naive and it will break at enterprise scale. The failure modes are wrong, silent, and expensive.
A better technique is to run on a neuro-symbolic framework. The agent has to work in concert with deterministic, battle-tested tools. The language model plans and reasons: it reads context, weighs options, decides the next step. Deterministic tools do the actual work: schema introspectors, lineage trackers, contract validators, replay engines.
For example, at WALT, the ingest agent runs on exactly this kind of neuro-symbolic architecture. Ingestion anomalies surface to the operator agent (covered in a separate piece), so the ingest agent has a clean handoff and doesn't try to be everything.
Bottomline: What this means for CDOs in 2026 and beyond
Stop thinking about ingestion as a connector decision. Start thinking about it as an operating-model decision.
The connector you choose will be replaced within five years. That is just the rhythm of the category. The operating model, whether humans or agents run the wrapping around the connector, will outlast every connector you ever buy. The connector was never the hard part. The work around it was, and that is exactly where an autonomous data engineering agent belongs.
Want to see what your ingestion layer looks like with an agent operating it? Book a demo today.



Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)