
We Built an AI Data Engineer to Bridge the Chasm Between Engineering, Stewardship, and Analytics
.webp)
There's a conversation happening in every data organization right now. It goes something like this:
"We have AWS, Snowflake, dbt, Tableau, a data catalog, a governance tool, and a team of expensive data engineers. Why does it still take four days to answer a basic business question about whether product X is doing well in North America?"
Because putting together an answer requires working across three roles. The data engineer handles the plumbing by handling ingestion across source systems, orchestrating ETL jobs, managing schemas, and keeping everything running at scale.
But plumbing alone isn’t enough. Answering a basic business question requires an understanding of the business and the metrics used to measure its performance.
Data analysts understand the business. They know that "doing well" means something different to the CMO (awareness and pipeline generated) than it does to the CFO (margin contribution against launch costs). They know that a new product launched in Q2 but didn't hit full distribution until mid-Q3, so any year-over-year comparison can be misleading.
Data stewards own the metrics. They define how "North America" is scoped (does it include Canada?). They maintain the canonical definition of revenue for a newly launched product versus an established one.
To answer "Is product X doing well in North America?", you need all three:
- The data engineer's pipelines to pull and join the right sources.
- The analyst's business context to frame what "doing well" means
- The steward's metric definitions to make sure the numbers are calculated correctly.
In most organizations, these are three diverse teams, and neither team speaks the other's language fluently. The result is a connective layer, i.e. the data context graph, that could tie all three together–the ontology, the knowledge graph, the semantic layer–never gets built properly.
Even when it does, this data context graph goes stale within months because nobody's job description includes fully owning and maintaining it.
The gap between three diverse roles and how enterprises dealt with it traditionally
The industry knows this gap exists. Back in 2024, Gartner identified this gap explicitly, recommending that CDAOs consider hiring a dedicated "knowledge engineer who focuses on developing ontologies, knowledge graphs, rules or other symbolic models to represent the collective intelligence of the organization."
Large enterprises fill this gap by hiring IT consulting firms. Infosys, TCS, and Wipro will build you a semantic layer and a data context graph. It takes 6 to 18 months, costs millions, and when the contract ends, the consultants leave and the institutional knowledge goes with them.
Even one of the most advanced AI companies in the world ran into this problem. OpenAI documented this problem in January 2026 when they published a detailed account of the bespoke data agent they built for internal use.
To make it work reliably on their own structured data, their engineers had to build six separate context layers and a custom enrichment pipeline. Their conclusion: even with the correct tables found, producing correct results is not guaranteed, because agents must reason about data relationships, joins, and filters that can silently invalidate results if applied incorrectly. OpenAI solved this for their own data estate with six context layers and the best data engineers on the planet. Most enterprises cannot replicate that build.
That’s where an AI data engineer makes a huge difference.
AI data engineer: The role that closes this gap and owns the data context graph end-to-end
An AI data engineer closes this gap because he understands the business, metrics, and can handle the plumbing. He can oversee everything from ingestion to transformation and governance.
The AI data engineer can build, maintain, and fully own the Data Context Graph that provides complete context on the business and governing metrics.
This AI data engineer isn’t a copilot suggesting code for a human to review. That’s AI-assisted engineering and in this scenario, the workload doesn’t shrink, just gets more complex as the copilot continuously flags problems for you to fix, adding to an already bloated workload.
An AI data engineer is your next hire–an autonomous agent that does the actual work of data engineering: pipeline building, transformation, schema evolution, data quality monitoring, lineage tracking, and governance. He understands plumbing, business vocabulary, metrics, governance policies, and can connect what the data engineer built and the data steward defined with what the data analyst needs.
When you ask a business question, the AI data engineer does the work, incorporates the fix, and hands you a report. Let's see how.
"What's driving margin compression this quarter?"
The AI data engineer resolves intent against the knowledge graph and returns trusted answers within hours.
“Why did the revenue drop 11% on Thursday?“
The AI data engineer notices the anomaly, runs RCA (root cause analysis) and traces it to a regional promotion that cannibalized full-price sales. The agent also recommends next steps and shares an action plan on Slack before the morning stand-up meeting.
“I need a PowerBI dashboard on last month’s revenue across all regions by tomorrow morning.”
The AI data engineer reads an analyst’s request, builds the logic from the Data Context Graph, deploys the dashboard in your existing BI tool, and sets up data quality checks. Your analyst can review the dashboard, refine (if needed), and present it right away. As a result, your senior data engineer’s job shifts from building every pipeline to reviewing what was built, which is how they should be spending their time.
Why is an AI data engineer more relevant now than ever before?
The IBM 2025 CDO Study, which surveyed 1,700 data leaders across 27 geographies, found that 77% of CDOs are struggling to fill key data roles, and only 53% say recruiting and retention efforts deliver the skills and experience needed. The McKinsey State of AI 2025, which surveyed 1,993 respondents across 105 countries, found that data engineers are among the most in-demand hires at large enterprises.
Meanwhile, Gartner predicts that by 2030, half of enterprises will face irreversible skill shortages in critical roles due to GenAI accuracy decline, skills erosion and uncompetitive pay. It’s tough to hire your way out of a problem that is scaling faster than any team can grow, given that the hiring process itself for most senior roles can take 12-18 months.
That's why the AI data engineer is going to be one of the most critical roles in the enterprise data stack.
To be clear: the AI data engineer doesn’t replace your data engineering team, but takes care of the grunt work–pipeline maintenance, the schema reconciliation, or the ticket queue. More importantly, the AI data engineer oversees the data context graph that nobody owns. Every AI initiative in the enterprise depends on this foundation, and every agent needs reliable, governed access to this foundation. When all that work is handled autonomously, engineers shift from firefighting to architecture, platform reliability, and the strategic work that actually scales the business.
How we bridge this gap with WALT, a collection of AI data engineering agents
We started with the Reasoner, the agent that builds and maintains the Data Context Graph. That was the core problem: nobody owned context, so we built an agent that takes ownership of the data context graph
But we quickly learned that you can't build context on data you haven't ingested. Some of our customers told us: "We don't even know if the data we need exists. Go find it first."
So we built a data acquisition agent that handles ingestion, source discovery, and schema evolution. What we've learned across customer deployments is that this pattern is not an edge case. As users and agents start interacting with enterprise data agentically, the problem isn't just a missing context graph. The data itself often doesn't exist in the gold layer. Sometimes it's not in the data warehouse at all.
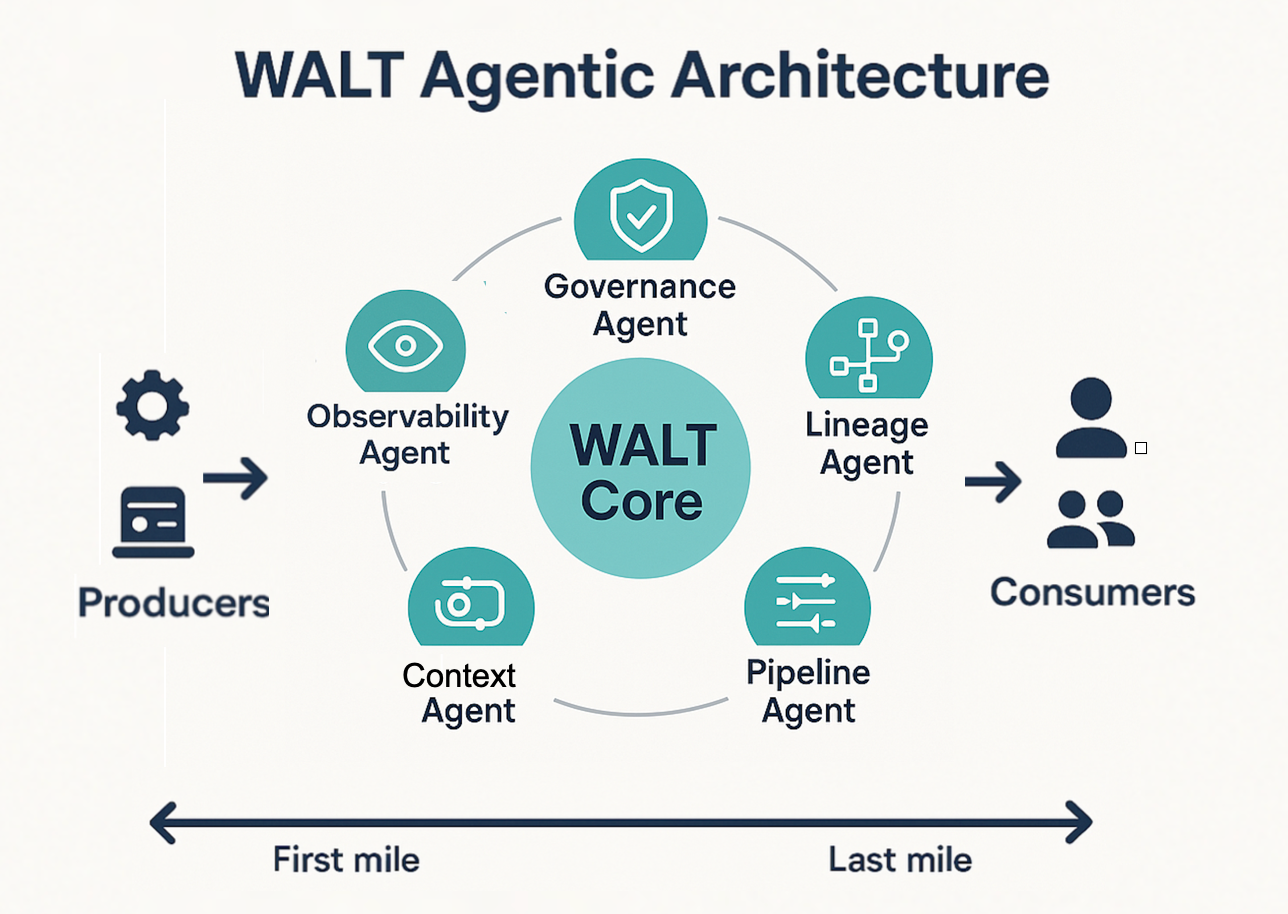
Gone are the days of waiting weeks for the business to get access to the data it needs. WALT's agents discover the data, ingest it, shape it, monitor it for quality, govern it, and deliver actionable insights. Here’s how each of WALT’s agents handles a distinct function of your data platform:
- Ingestor: Discovers, connects, and ingests data from any source, in any format, on any schedule. Handles schema evolution automatically.
- Transformer: Cleans, normalizes, and reshapes raw inputs into context-ready data models. Works with dbt or whatever transformation stack you already have.
- Reasoner: Builds, evaluates, and maintains the Data Context Graph: ontology, knowledge graph, and semantic layer. Enables agentic BI and downstream agent workflows through ReasonBase™.
- Operator: Monitors data quality, detects anomalies, and fixes pipeline issues before anyone notices. Handles freshness, completeness, accuracy, and cost optimization.
- Governor: Enforces access control, policies, and compliance. Manages schema migrations and platform evolution over time.
At the core lies a unified data context graph that every agent draws from and every downstream consumer, human or AI, queries through.
The architecture that makes this work is neuro-symbolic. LLMs handle intent classification, understanding what the user is asking. A deterministic engine constructs the SQL through a formal, auditable process. The result is 95% query accuracy across enterprise datasets in production.
WALT does the work and leaves
Enterprise buyers have been burned by vendors that create dependency. WALT does the work and leaves. The data, workflows, pipelines, graphs, and tribal knowledge all stay within your organization permanently. No vendor lock-in, compute tax, or artificial switching costs. You can end the engagement and retain every output.

Our customers have gone from zero infrastructure to a production-ready Data Context Graph in 8 weeks with WALT.
We’re at an inflection point in data engineering
For decades, data engineering, stewardship and data analytics have been separate because they required fundamentally different skill sets. That separation created a chasm, and in that chasm, most enterprise data problems have lived quietly, expensively, and without resolution.
The AI data engineer closes that gap for the first time. Not by replacing either discipline, but by owning the data context graph that serves as an independent virtual layer between all three, something no team was ever staffed to build.
The question every data leader needs to answer is not "should we automate data engineering?" It is: "Who owns the collective context that drives our engineering, stewardship, and analytics teams, and what happens when the answer is nobody?" An AI data engineer builds and maintains your data context graph at enterprise scale. He builds the foundation, keeps it current, and hands the ownership permanently to you.
Ready to hire your next data engineer?
FAQs about AI data engineer
1. Is an AI data engineer the same as a text-to-SQL tool?
No. A text-to-SQL tool takes a natural language question and generates SQL using an LLM. The output is stochastic: the same question can produce different queries and different answers on different runs.
An AI data engineer does not generate SQL at query time. He builds the reasoning infrastructure, the ontology, the knowledge graph, the semantic layer, that makes every downstream query deterministic and governed. The difference is between a tool that answers questions and an engineer that builds the foundation for questions to be answered correctly.
2. How is an AI data engineer different from a data catalog?
A data catalog tells you what data exists. It documents column names, ownership, and lineage, and it does that well. An AI data engineer builds and maintains the reasoning layer that tells every consumer, human or agent, what the data means, how it connects, and how to query it correctly. A catalog is a reference document, whereas an AI data engineer is an active AI agent who keeps the context current and exposes it to every downstream workflow automatically.
3. Can an AI data engineer handle messy, real-world enterprise data?
Yes. Real enterprise data is exactly the environment an AI data engineer is built for. An AI data engineer introspects your structured data estate as it exists, maps conflicting definitions, canonicalizes business concepts to authoritative sources, and flags ambiguities for human review before they propagate.
4. Will an AI data engineer replace my data engineering team?
No. An AI data engineer replaces the work your team should not be spending time on: ontology construction, lineage mapping, semantic modeling, schema evolution, and pipeline maintenance. These tasks consume over 60% of most data engineering teams' bandwidth without producing strategic value. When that work is handled autonomously, your engineers shift from firefighting to building data products that actually move the business. The team stays and focuses on strategic tasks, rather than ticket resolution and pipeline maintenance.
5. How long does it take to deploy an AI data engineer?
An AI data engineer like WALT goes from zero infrastructure to a production-ready Data Context Graph in 8 weeks. That compares to 6 to 18 months for a manually built data context graph delivered by an IT consulting firm. The speed difference comes from automation: WALT introspects your data, constructs the ontology, harvests KPIs from existing BI tools, and builds the semantic layer autonomously rather than relying on human data engineers to do each step sequentially.
6. How is an AI data engineer different from hiring an IT consulting firm?
An IT consulting firm will build you a semantic layer and data context infrastructure over 6 to 18 months, at a cost in the millions. When the engagement ends, the engineers leave and the institutional knowledge they accumulated goes with them. The documentation left behind describes a data estate that has already changed. An AI data engineer (like WALT) can deliver the same output within weeks, at a fraction of the cost, and everything that gets built stays permanently within your organization. More importantly, the AI data engineer keeps the context current continuously, as a living system.
7. What happens to everything WALT builds if we wish to stop this engagement?
Everything stays with your organization, permanently. The Data Context Graph, the pipelines, the ontology, the semantic layer, and the tribal knowledge WALT encodes all live within your own infrastructure. WALT does the work and leaves. There is no vendor lock-in, no compute dependency, and no proprietary format that prevents you from continuing to use what was built. You can end the engagement and retain full ownership of every output.


Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)