
Medallion Is a Pattern, Not a Platform. The Real Question Is Who Builds & Runs It.
.webp)
In 2026, who builds and operates the medallion is more important than the warehouse you choose.
The medallion is a design pattern, not a product. Databricks is clear about this in its own documentation, which calls medallion a data design pattern and notes that it’s a recommended practice rather than a requirement. Bronze (raw), silver (validated), and gold (enriched) are terms describing the data quality in each of these layers.
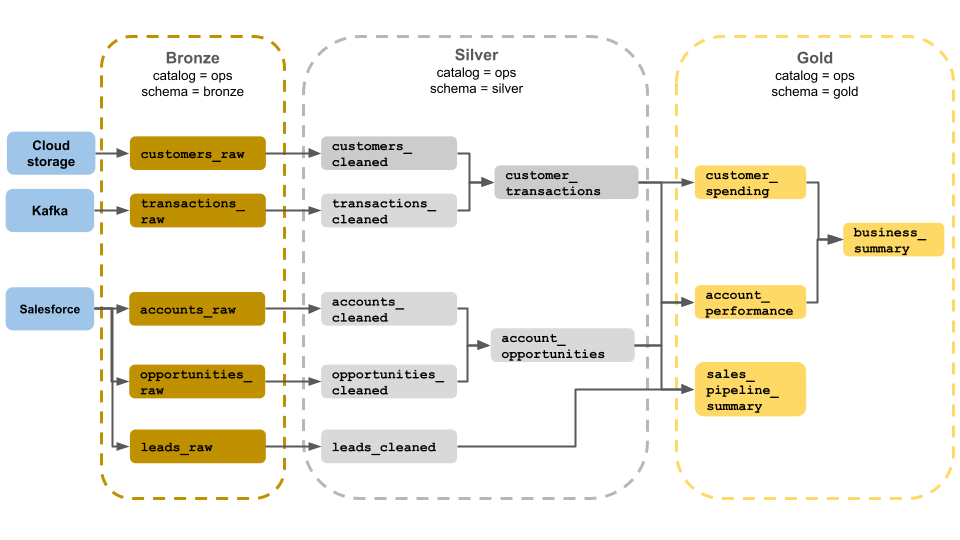
A pattern describes how you organize work. It works on whatever stack you already run. You don’t buy it, and you don’t have to migrate to reach it. While the pattern and terms might seem modern, the concepts they represent are a lot older. Raw data lands somewhere, gets cleaned and conformed, then modeled into business shapes, and served to people who need answers. That sequence has run inside enterprise data warehouses for the last 30 years, under different names, with the same underlying logic.
Anyone can get to medallion
Medallion runs on whatever you operate today. Databricks, Snowflake, BigQuery, Redshift, Iceberg tables on object storage, Teradata, even on-premise SQL Server with stored procedures: every one of these can host a credible medallion implementation.
You can even achieve medallion with a heterogeneous data estate. The reality today is that we all have data fragmented across different platforms. While we have been led to believe that fragmentation is bad and centralizing is the nirvana, this is not true. We got to fragmentation because the leaders at the time made a cautious choice to prioritize just the work load that needs to move to a new platform based on budget and timeline.
Centralizing and increasing data gravity was a popular choice before AI. But now you no longer have to go that stage. You can embrace the fragmentation and get to medallion. A federated or distributed medallion is the future.
As we mentioned earlier, medallion is a pattern and patterns are portable. The vendor logo on the slide doesn’t decide whether you get there. The only reasons to debate picking one stack over another are cost, separation of storage and compute, open formats, ecosystem, regulatory posture, and operational maturity. "We need to do medallion" isn’t one of them.
CDOs who frame their program as "first we migrate to Snowflake/Databricks, then we implement medallion" are conflating two unrelated decisions and adding a multi-quarter migration program to a critical path that didn't need it.
What is the right question to ask?
“Who designs, builds, and operates the layers?”
For two decades, humans designed, built, and maintained every layer of the medallion architecture with pipeline tooling. In the era of autonomous agents, that changes. The autonomous data engineer (ADE) builds, operates, and evolves a data platform with agents as the primary actors. Humans contribute intent and judgment, not plumbing.
Let’s see what changes when agents build these layers, while humans supervise escalations as and when needed.
Bronze becomes a landing zone that maintains itself
The connector itself is now a managed product. Fivetran, Airbyte, and Databricks Lakeflow Connect have turned source connection into a managed product you configure rather than build. WALT's Ingestor orchestrates those tools rather than competing with them.
The biggest challenge with the Bronze layer is the work around the connector: source discovery, schema-drift handling, back-pressure, PII classification at ingest, late-arriving data, replay logic. Agents take over all that plumbing and transform Bronze into a landing zone that keeps adjusting itself, rather than a one-time engineering build.
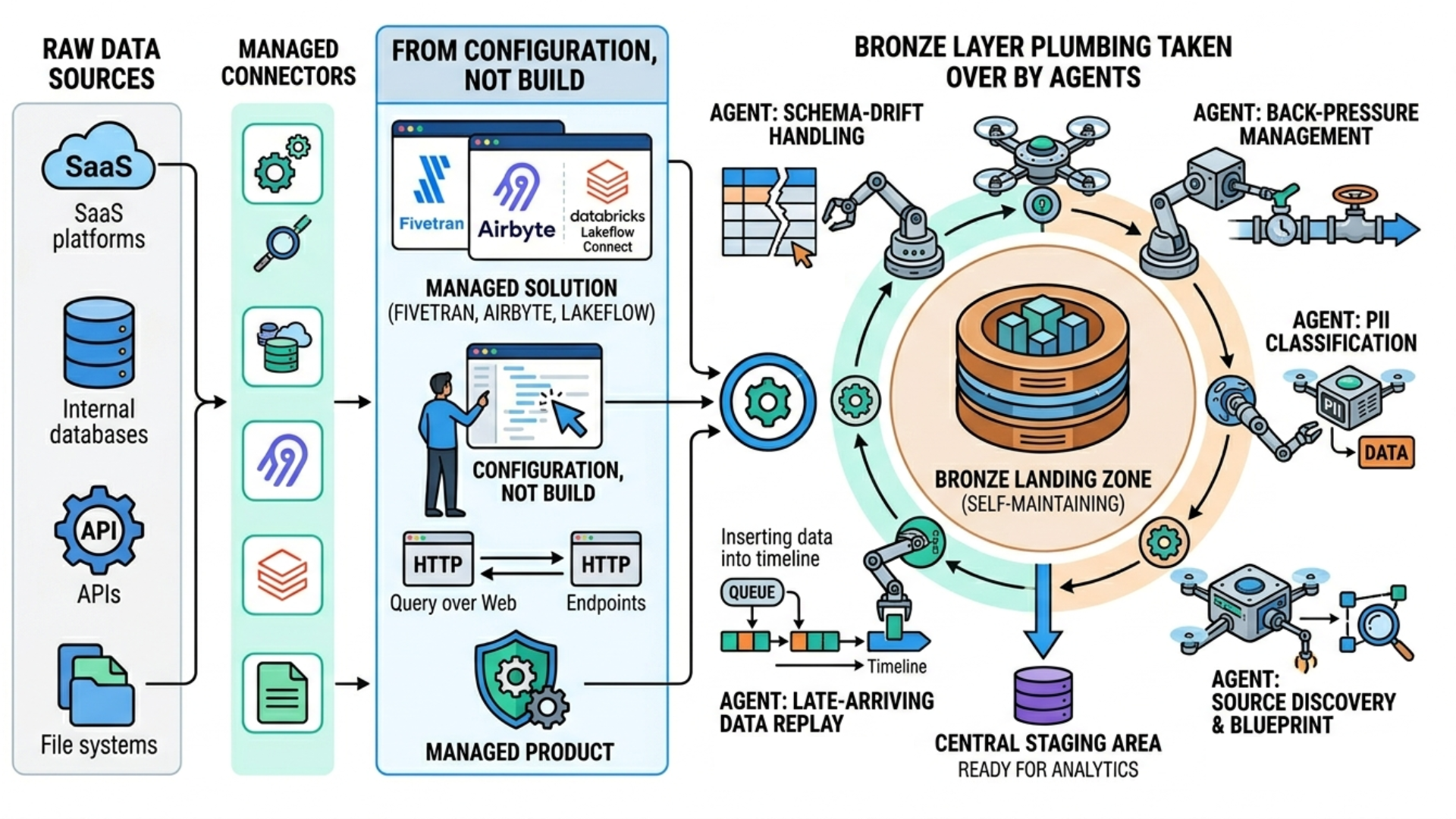
Silver becomes a conversation between agents and people
The mechanical work — type-casting, deduplication, standardization — becomes something agents propose and humans approve via CI/CD.
The harder part, i.e., joining across sources, slowly changing dimensions, identity resolution, becomes a back-and-forth between an agent and a subject-matter expert (SME). The agent writes the SQL/Pyspark, while the human supplies the judgment about what is actually correct.
The agent doesn’t replace the human, but accelerates the transformation workflows and ensures that the layer stays continuously updated.
As a result, "we have Silver" stops meaning "we ran the first pass and called it done," and starts meaning a layer that keeps pace with the sources feeding it.
Gold gets shaped by what the business actually needs
Bronze and Silver are, at their core, engineering problems. Hard ones, but tractable: move the data, clean it, conform it, test it. Gold is a different kind of problem.
Gold is where raw fields turn into "net revenue," "active customer," "first-pass yield." Those definitions carry business meaning, and business meaning gets contested. Finance and risk define "revenue" differently. A CFO and a marketing lead mean different things by the word "visibility." That is why medallion programs stall at Gold, especially with the old approach of upfront specification.
The old approach specifies Gold upfront. A team spends months designing every mart, dimension, and metric before a single business user asks a question. By the time it ships, the business has moved, making half the tables redundant.
Gold is where raw fields turn into "net revenue," "active customer," "first-pass yield." Those definitions carry business meaning, and business meaning gets contested. Finance and risk define "revenue" differently. A CFO and a marketing lead mean different things by the word "visibility." That is why medallion programs stall at Gold. You have to resolve semantics, govern them, and keep them resolved as the business changes.
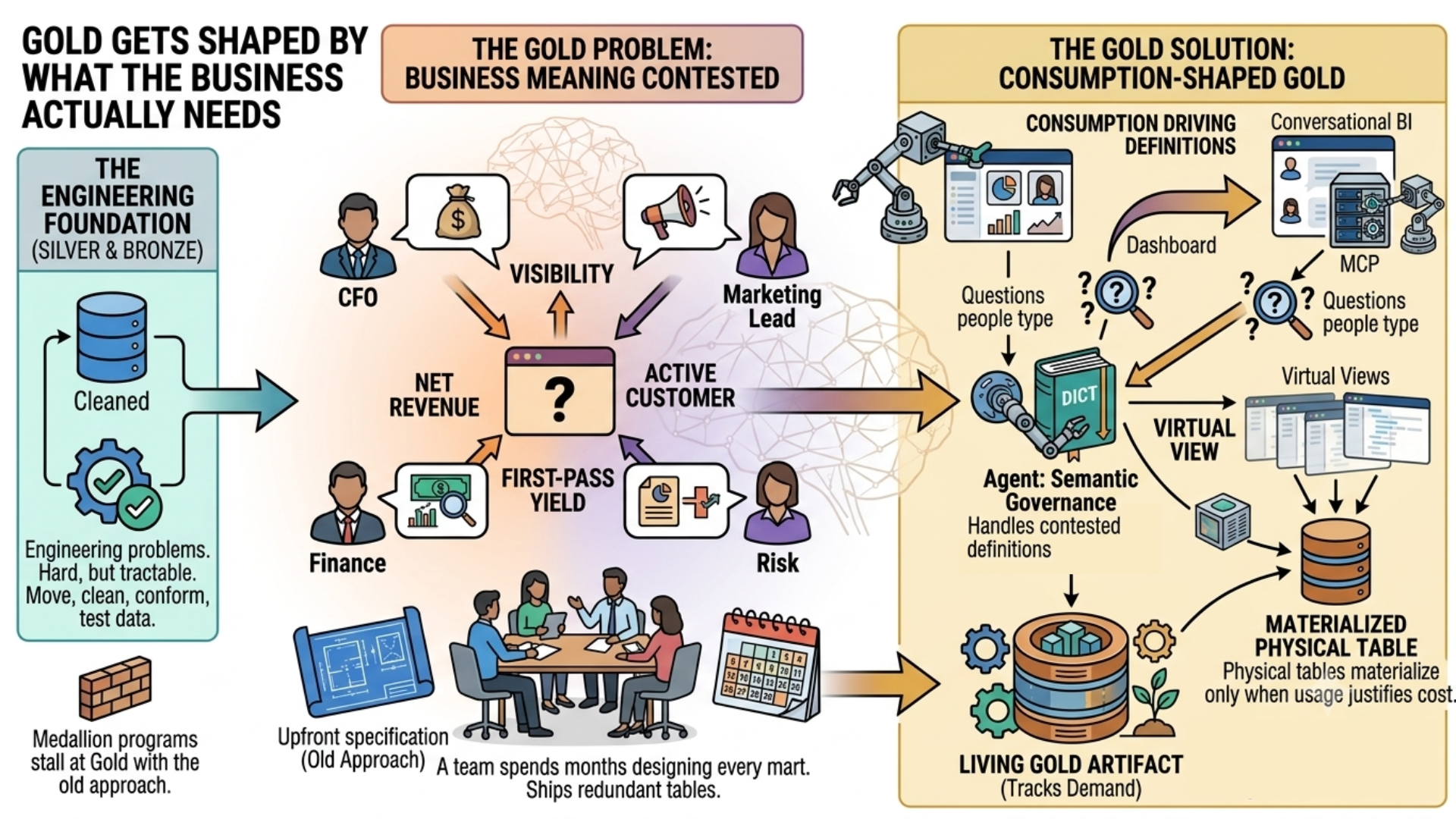
With agents, consumption shapes Gold. Definitions emerge from what people actually ask for: the questions people type into dashboards, into conversational BI, into MCP calls made by other agents. Views replace pre-built tables. Physical tables materialize only when usage justifies the cost. Gold becomes a living artifact that tracks demand, instead of a deliverable that goes stale on arrival.
The cross-cutting work is where agents change the most
The unglamorous work is where agents shift the daily reality most:
- Lineage: Built and read by agents, so nobody has to trace a dependency graph by hand to work out what a schema change will break across systems.
- Data quality: A freshness or completeness failure becomes an incident the operator agent diagnoses and resolves, often before anyone gets paged.
- Schema drift and backfills: Late data and breaking changes stop being 3 AM emergencies and become routine, logged, auditable operations.
This is the part of medallion that eats most of a data team's week. Handled by agents, it is also the part that frees that team to build something.
Meet WALT, the world’s first autonomous data engineer
WALT is a collection of five autonomous data engineering agents that run on top of your current stack. WALT’s autonomous data engineers reuse your dbt models and feed your Tableau and Power BI dashboards, so the stack you already paid for works harder.
WALT’s Transformer does the work of Silver, Gold, and Platinum. It type-casts and deduplicates, conforms dimensions, and reshapes raw inputs into business models. It is topology-agnostic, writes transformation code in your platform's native language and reuses your dbt setup (where one exists).
Two things make the Transformer's Gold layer different from a manual one.
First, it is consumption-driven. Rather than specifying Gold upfront, the Transformer starts from the questions your teams actually ask and the dashboards they already run. It propagates attributes through Silver to Gold to the semantic layer, building only the shapes the business needs and extending your existing models instead of replacing them.
Second, it is governed by meaning. The Transformer works alongside WALT's Reasoner, the agent that builds the Data Context Graph (ReasonBase™): the ontology, knowledge graph, and semantic layer that hold what your business terms mean.
For the engineers who got burned by the last tool promising total autonomy, two design choices matter.
1. Deterministic output: An LLM only classifies what a question is asking. A deterministic engine builds the SQL. Same question, same SQL, same answer, every time. An LLM never writes your production query.
2. Human in control: Every transformation and definition WALT proposes is written in human-readable form for your team to review, version, and approve through normal CI/CD. Agents propose. Your engineers decide.
WALT does not remove your data engineering team.
WALT takes over the part of medallion that has kept your data engineers buried in plumbing work for years: the manual layer-by-layer propagation, the maintenance tickets, the schema-change firefighting. WALT customers see 95% query accuracy across enterprise datasets and a 40% cut in report creation time and cost at a $4 billion enterprise, going from zero infrastructure to a production-ready platform in 8 weeks.
What does this look like in practice?
Building the mart nobody asked for yet
When the Transformer saw the same set of joins show up across 40 ad-hoc queries in two weeks, it built the mart, deployed it, and made the next report run about ten times faster.
Pruning attributes down to what gets used
In one mart with 200 attributes, only 30 were ever queried. The Transformer pruned the rest and cut compute by 40%. Nobody noticed the change, except the CFO who saw the bill.
Surviving a schema change without the fire drill
When an upstream source changed its schema and two dashboards sat in the blast radius, the Transformer rewrote the affected Gold models, updated the data contract, and shipped a clean pull request before anyone opened Slack.
The decision CDOs must make now: Who implements and operates the medallion?
A platform choice has a half-life of maybe five years. You will revisit it. Costs shift, table formats open up, a better option appears.
The operating-model choice, humans or agents building your layers, has a half-life closer to a decade. It shapes how your team spends every week, how fast the business gets answers, and whether your data foundation can keep pace with the demand coming from agents.
So sequence the two decisions in the right order. The operating model comes first, and the platform comes last.
Medallion is the diagram everyone agrees on. The interesting question isn't where you draw it. It's who builds it, and that will define the next decade of your data platform.
If your Gold layer keeps drifting and your team keeps firefighting, the platform is not the thing that needs fixing. See how WALT's Transformer and Reasoner (autonomous data engineering agents) build and maintain a live Gold layer on the stack you already run. Book a demo and bring your messiest business questions.


Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)