Enterprise leaders have poured billions into AI with the promise of smarter decisions, lower costs, and new revenue streams. Yet most organizations still don’t see durable value at scale. Multiple large-scale studies have found that only a small minority of companies realize significant financial benefits from AI programs; in fact, a long-running MIT Sloan Management Review and BCG series reports only about 1 in 10 companies achieve substantial financial gains from AI initiatives. https://sloanreview.mit.edu/projects/expanding-ais-impact-with-organizational-learning
What explains the gap between pilot excitement and production reality? The headlines often blame “AI immaturity,” “lack of use cases,” or “talent shortages.” Those matter, but they’re not the core blocker. The single biggest reason enterprise AI underperforms is painfully simple: your structured data isn’t AI-ready. When underlying data is fragmented, inconsistently defined, duplicated, or stranded in legacy silos, production AI collapses under the weight of contradictions.
Below, we unpack why production failure is so common, show how reputable studies back this up, and outline a pragmatic path forward.
The Production Gap Is Real (and Measurable)
- Only 10% see significant value. Across years of research, MIT Sloan Management Review and BCG have consistently found that only about 10% of organizations unlock major financial benefits from AI; most report little or no value. That’s not an “early adopter” problem; it’s an operating-model and data problem. https://sloanreview.mit.edu/projects/expanding-ais-impact-with-organizational-learning/?utm_source=chatgpt.com
- Pilots die before scale. IDC’s global studies show many AI pilots never reach production or stall quickly; even when they do, insufficient data infrastructure and operations are frequent failure causes. https://www.netapp.com/media/107000-wp-scaling-ai-initiatives.pdf?utm_source=chatgpt.com
- GenAI hasn’t changed the fundamentals. Recent reporting on a new MIT study notes that the vast majority of enterprise GenAI implementations show no measurable impact on P&L due largely to poor integration with existing processes and data flows, not algorithmic shortcomings.
The lesson: advanced models can’t outrun basic data problems.
The Hidden Culprit: Enterprise Data Isn’t AI-Ready
Enterprises rarely suffer from too little data. They suffer from too many versions of the truth:
- Siloed systems and duplicate records. A single customer, product, or asset often appears with different IDs and attributes across policy, billing, CRM, ERP, data warehouse, and analytics marts. Recommendation engines, fraud models, and assistants get contradictory signals — and users lose trust.
- Conflicting KPI definitions. “On-time,” “closed,” “active,” “churn,” “CLV,” and “inventory availability” can mean different things in different business units. Dashboards disagree, models drift, and explanations fall apart.
- Schema drift and lineage gaps. Over years of mergers, replatforms, and local optimizations, column meanings diverge, transformations are undocumented, and lineage breaks. Models trained on yesterday’s logic fail when today’s fields change.
- Unstructured/semistructured blind spots. Claims notes, call transcripts, emails, PDFs, and logs contain high-signal context but aren’t normalized for downstream use, starving AI systems of context.
These issues are so pervasive that leading practitioners now treat data readiness as the prerequisite for any meaningful AI scale-up. Capgemini’s Research Institute emphasizes data foundations, data standards, and AI-readiness of enterprise data — explicitly calling out the need for high-quality data and common data standards to integrate AI reliably across platforms. https://www.capgemini.com/wp-content/uploads/2024/08/CRI_Data-powered-enterprises_22082024-V1.pdf?utm_source=chatgpt.com
IDC echoes the same point from a systems angle: without intelligent data infrastructure, failure rates spike and pilots stall; where organizations mature their data pipelines and platforms, failure rates drop materially. https://www.netapp.com/media/107000-wp-scaling-ai-initiatives.pdf?utm_source=chatgpt.com
Why “Model-First” Approaches Keep Failing
If your AI strategy begins with “pick a model,” expect pain later. Three recurring patterns sink production efforts:
- Model accuracy without agreement. A model can be accurate in cross-validation yet still fail in production if downstream teams don’t agree on inputs and definitions. Accuracy isn’t the same as governed, explainable, and reconcilable outputs aligned to enterprise metrics.
- Automation without context. GenAI copilots and agents do great demos, but without access to canonical, governed context — consistent entities, metrics, and business rules — assistants hallucinate, agents mis-act, and “shadow logic” proliferates.
- Scaling without standards. Each new use case invents its own mappings and metric definitions. Costs compound, cycles slow, and new models re-ignite old arguments about whose numbers are “right.”
Result: promising pilots that never become dependable systems of record.
The Data Readiness Checklist (What High Performers Do)
Leaders who get past the pilot phase share a consistent playbook grounded in data readiness and organizational learning:
- Canonicalize core entities and metrics. Create governed, shared definitions for customers, products, locations, assets, claims, orders, policies — and for the KPIs that matter. (Capgemini highlights common data standards as a prerequisite for interoperable AI.)
- Deduplicate and reconcile records. Resolve entity matches across CRMs, ERPs, data lakes, and apps to establish a single source of truth for critical objects.
- Codify business rules as machine-readable semantics. Move policy logic and KPI calculations out of slide decks and spreadsheets into a reasoning layer that applications and models can reuse.
- Harden the data platform and lineage. Invest in versioned schemas, quality monitors, lineage tracking, and change management so models don’t silently break when upstream shifts.
- Close the loop between humans and AI. The MIT/BCG research is clear: organizations realize value when AI systems and humans learn from each other, operationally and culturally. https://sloanreview.mit.edu/projects/expanding-ais-impact-with-organizational-learning/?utm_source=chatgpt.com
Do these well, and those scary failure statistics start to look solvable instead of inevitable.
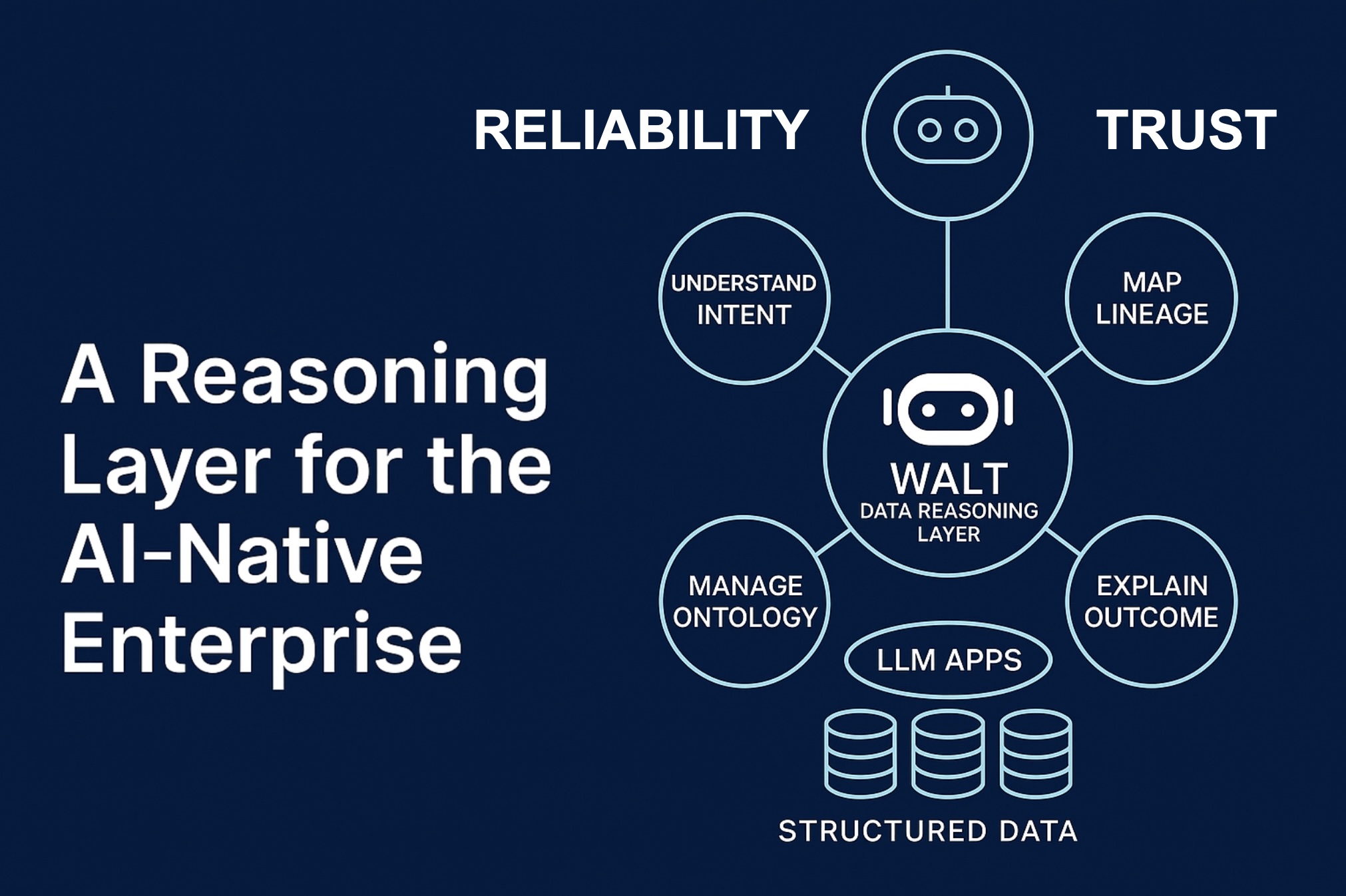
A Practical Way Forward: WALT AI’s Virtual Context Engineer
Most organizations know they need canonical data and governed semantics; the friction is how to build and maintain that layer continuously while the business keeps changing. This is the gap WALT AI was designed to fill.
WALT’s virtual context engineer creates a data reasoning layer — the ReasonBase™ — that sits above your existing systems and continuously reconciles the inconsistencies that derail AI in production:
- Entity reconciliation & deduplication. WALT merges duplicate customers, products, assets, or policies across systems, generating stable, governed IDs that downstream models and apps can trust.
- KPI and policy canonicalization. It captures the business logic behind metrics (e.g., “claim closed,” “on-time,” “churn,” “fill rate”), expresses those rules as machine-readable semantics, and enforces them consistently across BI, ML, and GenAI use cases.
- Context enrichment for GenAI and agents. By exposing a unified, governed context to assistants and agentic workflows, WALT reduces hallucinations and contradictory answers — a key factor behind weak GenAI P&L impact, according to recent MIT-covered reporting.
- Change-aware governance. When upstream schemas or definitions change, WALT propagates updates through the ReasonBase and alerts dependent models, dashboards, and prompts, preventing silent degradation.
- Plug-in to your current stack. You don’t have to rip and replace data platforms. WALT layers onto warehouses/lakes, MDM, catalog/lineage tools, and MLOps systems to make the existing stack behave coherently.
The outcome is straightforward: AI that runs on a single, trusted version of the truth — across analytics, ML, and GenAI.
Conclusion: Make Your Data Make Sense — Then AI Makes Money
The sobering reality is that most enterprises still don’t capture meaningful value from AI at scale — not because AI algorithms don’t work, but because the data and semantics feeding them aren’t production-ready. Long-running research from MIT Sloan Management Review and BCG shows only about 10% of firms get significant financial benefits; IDC points to data infrastructure and readiness as a decisive factor separating successful deployments from stalled pilots.
Capgemini’s latest guidance is equally clear: to unlock AI at scale (including agentic AI), organizations must ensure AI-readiness of enterprise data, adopt common data standards, and strengthen data foundations.
WALT AI’s virtual context engineer tackles that root cause by building a ReasonBase™ — a living data reasoning layer that reconciles anomalies across complex enterprise systems, standardizes KPIs and entities, and gives AI a consistent, governed context. With clean semantics and canonical data, AI stops amplifying chaos and starts delivering trusted answers, measurable ROI, and durable competitive advantage.
If you want your next AI deployment to be in the 10% that works, start by making your data make sense — and let WALT do the heavy lifting.