
Why Context-Layer-Only Companies Are Repeating The Catalog Mistake
.webp)
In January 2026, OpenAI published a detailed account of their in-house data agent, built around multiple layers of context grounded in OpenAI’s data and institutional knowledge. Most takeaways from this story focused on their six context layers: schema metadata, curated table descriptions, tribal knowledge mined from Slack and Notion, code-level inference, vector retrieval, and memory.
While context is everything, it is only half the story. OpenAI did serious work on the inference engine itself, with the same rigor they put into context. They built an always-on, self-learning agent that investigates failures, adjusts its approach, and carries full context and learnings forward between steps.
The agent doing inference work that a human analyst would do is the model worth copying. That’s exactly what the new wave of context-layer-only companies is missing.
The rise of dedicated context layers in 2026
In the last six months, every major data platform vendor has shipped a context layer:
-- Snowflake released Semantic Views as the foundation for Cortex Analyst.
-- Google Cloud just launched the Knowledge Catalog, evolving Dataplex into what they call a "universal context engine."
-- Databricks merged Genie Spaces, Unity Catalog metric views, and dashboards into a single agentic chat surface.
-- Other prominent catalog vendors have repositioned themselves as context layers.
The pitch is the same in every case. Bring your metadata together, define your metrics, plug in an LLM, get reliable agentic answers. The recommended setup is to:
1. Build a rich context layer: Semantic views, knowledge graphs, metric definitions, curated examples.
2. Layer on guardrails: Verified queries, prompt matching, knowledge stores, instruction sets.
3. Hand off to a hosted LLM: The model reads the context, applies the guardrails, and generates SQL at runtime.

Shipping a context layer is not the same as building one.
Buying a context layer solution is like purchasing Excel and calling it your budget model. The spreadsheet exists, but the model has to be built by you. Similarly, when you buy the context layer, everything from the ontology to the metric layer is empty. Populating them requires months of data engineering work: introspecting your warehouse, mapping relationships, resolving semantics, capturing tribal knowledge, etc.
To make sense of your structured data, we built WALT’s Reasoner, one of five agents in the collective. Reasoner introspects your data, maps entity relationships, canonicalizes business terms, and builds the full data context graph within days, not months.
But even that’s not enough. Getting the context built isn’t the same as getting the context right. And the only way to know if it's right is to put it to work.
Putting context to work means answering real questions with real SQL, live, in front of your CEO. That's where the context layer model breaks down. The same question might get different answers depending on the model version or prompt phrasing. You cannot explain why you get different answers as you cannot see what inference is being made. That’s why the context layer alone isn’t sufficient.
The two things context-only players are forgetting:
1. Context without inference is just a catalog.
2. Inference is the only signal that tells you whether the context is accurate or needs to mutate.
Let’s explore each of these aspects further.
Context without inference is just a catalog
Data catalogs went stale because they were an afterthought, populated once and never updated. By the time anyone consulted it, half the entries described tables that had been renamed, dropped, or split. So, data consumers asking a question went to the data engineers, who queried the warehouse, and not the catalog.
Decoupling context from inference repeats the same mistake under a new name. A "context layer" sitting separately from the system answering the question is yet another catalog.
Inference is the most important signal for context accuracy
The best way to validate context is by watching what gets inferred from it.
A regional VP asks for "active customers in EMEA." The agent returns 14,000. Sales leadership knows the real number is closer to 9,000. The semantic view defined "active" as "any account with a login in the last 90 days." The business actually meant "any account with revenue in the current quarter." While both definitions are valid, the ambiguity leads to incorrect answers.
Inference on structured data, producing deterministic, trustworthy output, is genuinely hard. You may have two fields: "Boondocs" and "Boondocks Inc.” Reconciling both values as the same across source systems, workflows, and downstream dashboards is a real data engineering problem.
For both examples above, a context layer alone isn’t enough as the context didn’t fail in the catalog when it was authored. The failure mode revealed itself when inference exposed the gap.
Inference is also the signal for what the context needs to become. A new business question reveals a missing definition. A query that returns the wrong join exposes a bad relationship. A question routed to the wrong table shows a gap in the ontology. Without inference in the loop, the context layer drifts silently, eventually becoming outdated and irrelevant, exactly like catalogs. Some vendors are offering to build the context layer semi-autonomously. Without tackling the inference aspect, they’ll merely automate the production of stale catalogs faster.
Why this isn't the same as LLM code generation
It's one thing to have an LLM write Python, validate it offline, and run it a thousand times in production. The LLM made one stochastic choice and a human data engineer validated it. If the model doesn’t work well and produces a worse version of the function, the worst case is an engineer pushing back during code review.
It's another thing entirely when your CEO asks a question and the inference system writes SQL live. The question and the SQL exist in the same instant, and there’s no code review or offline validation.
When you ask the same question again a week later, you may get an entirely different SQL with different joins and filter logic. This happens because LLMs are stochastic by nature as they’re built on transformer-based models. Even at temperature zero, a transformer-based model relies on probability distributions over tokens, and probability distributions produce variation. A stochastic system can't audit itself, and a context layer can't audit a query that hasn't been written yet.
Let’s go back to the CEO asking the same question twice and getting different results. The data engineer has no way to know what SQL the LLM generated the first time as it didn't log its reasoning. To ensure that the CEO has the right numbers, the engineer ends up conducting a 3-hour root-cause analysis to understand which answer is correct. This approach doesn’t scale.
How WALT tackles the inference problem with neuro-symbolic AI
Neuro-symbolic AI combines the language understanding of LLMs with a deterministic inference engine to get consistent, auditable outputs.
WALT's neuro-symbolic AI blends the LLM's stochastic neural reasoning with a deterministic analytical inference engine — to produce safe, consistent inference over your data. There will be no runaway queries taking down your clusters.
WALT uses LLMs only for intent classification: understanding what the user is asking, resolving ambiguity, selecting the right analytical pattern. SQL is then constructed using SLMs, which work through formal logic. The output is the same SQL for the same interpretation, every time.
The three components of SLMs or Stable Logic Models
WALT’s SLMs (Stable Logic Models) are made up of ReasonBase™ (data context graph), logic models, and the AST SQL Compiler.
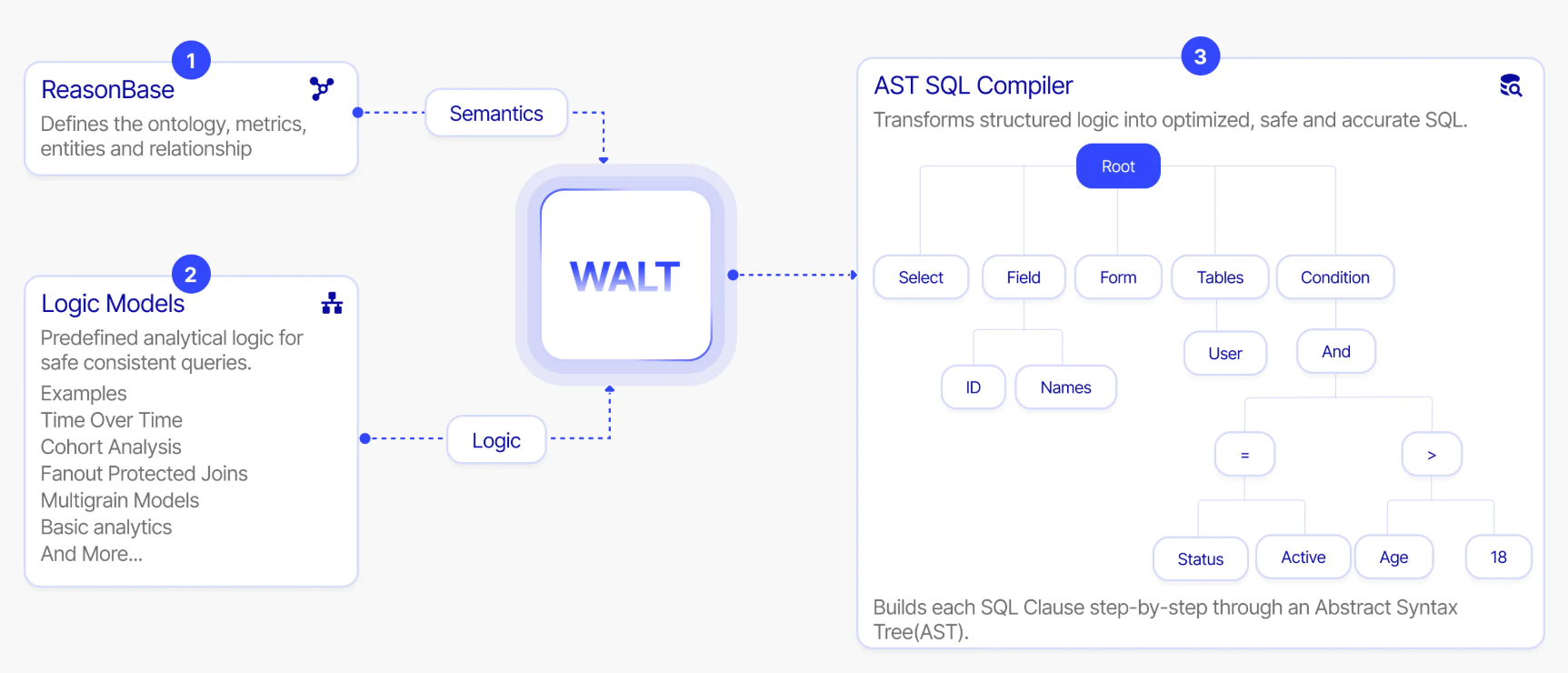
1. ReasonBase™: Lays the semantic foundation for reasoning by defining ontology, metrics, entities, and relationships across your enterprise.
2. Logic Models: Predefined analytical patterns including time-over-time comparisons, cohort analysis, fanout-protected joins, and multigrain models. These encode safe, proven query structures as deterministic logic that the system can compose and verify.
3. AST (Abstract Syntax Tree) SQL compiler: Transforms structured logic into optimized SQL through an abstract syntax tree, building each clause step by step. Every query is traceable back to the exact logic model and semantic definition that produced it. AST-level analysis is the most reliable method for detecting errors in LLM-generated SQL, precisely because it operates on the structure of the query, not its surface text.
The LLM's role is interpretation and not generation. It understands what you’re asking. The symbolic system handles correctness, consistency, and auditability.
What neuro-symbolic looks like in production
Take a real example. A user types: "How is Boondocs doing in NA?"
Two problems hit at once. We don't know how "Boondocs" is stored in the database (it might be "Boondocks Inc.", "BOONDOCKS", or a product code). And we don't know which column or table holds it (customer name, product line, brand, or something else entirely). We don't know either side of the WHERE clause. An LLM will guess. Guessing here produces queries that return empty results or, worse, wrong data that looks right.
WALT's approach is neuro-symbolic. When the user says "Boondocs," the neural component resolves it to the closest matching value in the index ("Boondocks Inc." in the customer_name column). The symbolic component applies that resolution as an exact filter in the generated SQL. That's the difference between a system that reasons and one that runs on guesswork.
The next problem isn't context.
Context-layer-only companies are betting that catalog and metadata hold the answers to users' questions. We're seeing a deeper issue as users converse with agents in natural language.
Go back to the Boondocs example. Inference worked. The context was right. And we still didn't know either side of the WHERE clause before a single line of SQL could be written. That's neither a context problem, nor an inference problem. It's something neither catalogs nor context layers were built to solve. We'll cover that in the next piece.
If your team is evaluating how to make structured enterprise data actually agent-ready, see WALT in action.



Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)