
Platform-Native Agents vs. Autonomous Data Engineers: One Assists Your Engineers, the Other Builds & Runs Your Estate
.webp)
Every data platform now ships an agent. This week, thousands of data leaders will watch slick demos and ask a fair question: "Doesn't this do what an autonomous data engineer does?"
The short answer is no. The long answer requires looking past the keynote and evaluating who operates the agent, what the tokens actually pay for, and who answers when the agent is wrong.
Platform-native agent vs. autonomous data engineer: What's the difference?
Two terms run through this whole piece, so let's pin them down first.
- Platform-native agent: An agent embedded inside a specific vendor's environment that relies heavily on a human operator to provide context and logic.
- Autonomous data engineer: A stack-agnostic AI agent (or, like WALT’s crew of AI agents) that autonomously discovers, models, heals, and governs data across a heterogeneous estate without persistent human prompting.
We respect the engineering behind the platform agents. These platforms are excellent infrastructure, and WALT builds on them every day. The difference isn't whether their agents work. It's a set of structural questions that no demo answers.
5 questions every agent demo avoids
It's conference season. Every data platform, from warehouses and lakehouses to transformation frameworks, ingestion tools, and orchestrators, now ships an agent. The demos are good. The keynotes are better.
Buyers are walking out of sessions asking us, "My platform vendor says their agent does all of this. How is WALT different?"
It's a fair question, and we answer it the same way every time. Ask the platform vendors these five things, and the difference stops being subtle:
1. Who operates the agent?
2. What do the tokens actually pay for?
3. Does the agent know what good looks like for your business?
4. Whose interests is it architecturally aligned with?
5. When the agent gets the answer wrong, who is responsible?
Are platform-native agents actually autonomous? Keynotes vs. setup documentation
Pull up the setup documentation for any platform-native agent and read it next to the keynote.
The keynote says autonomous. The setup guide says: curate a scoped collection of tables. Write instructions encoding your business logic. Provide tested example queries; the docs typically recommend at least five. Define benchmark questions to score the agent against. Add verified queries for the questions you expect users to ask, so the agent can bypass generation entirely for anything important. Assign an admin to review flagged answers and iterate.
All of the above is responsible product design. But notice what it describes: a copilot that assumes the presence of a skilled human operator. Because someone has to do that curation, and that someone is a data engineer or analyst, one you hire or one whose cycles you redirect from the backlog.
That’s the first structural issue: the operating model assumes that a human does the curation.
The vendors' own numbers make the point better than we can. Published implementation write-ups show these agents answering barely half of questions correctly out of the box, reaching reliability only after weeks of systematic curation, annotation, and benchmarking.
One platform's own benchmark shows a raw LLM at roughly 51% accuracy on enterprise questions, jumping past 90% once a human-built semantic model is added.
Why human-built semantic models carry the accuracy, rather than the agent
Read that result carefully. The human-encoded context carries the accuracy. The agent is the delivery mechanism. This agent is a productivity tool for the team you already couldn't hire enough of.
There's nothing wrong with productivity tools. But if the pitch is "this replaces the data engineering labor," and the setup guide depends on that same labor to work, the pitch and the product are describing two different things.
Notice what the operator model means for accountability. When a copilot's answer is wrong, the human who prompted and curated it owns that mistake, every time, forever. The platform sold you a tool; the responsibility stayed with your team.
A true autonomous data engineer is answerable for its own output: it has to show its lineage, prove its logic, and stand behind the number. That's the difference between buying assistance and hiring an engineer.
For the agents that go beyond Q&A into pipeline building (the newest generation, most of them months old), read the fine print on autonomy: background operation "coming soon," observability agents “on the roadmap”, autonomous modes “in beta”, “labs”, and “research preview”.
As of this writing, what's shipped is assistance; autonomy is on the slide.
Why data is not software (and codegen is not the moat)
The second structural issue is what is being actually sold.
Strip away the branding and a platform-native agent is a frontier LLM, prompted well, operating inside one vendor's environment. The LLM is the same one you can rent directly from the frontier lab that built it (OpenAI, Anthropic, Google).
Frontier models already know these platforms. They've read the docs, the forums, every public repo. Any competent coding agent can write Spark, SQL, or pipeline configs for any major platform. Code generation is commoditized, for the platforms, for us, for everyone.
So buying codegen from your platform vendor doesn't get you something the open market doesn't already offer. What you get is codegen that’s anchored: to one platform's catalog, one platform's context layer, one platform's meter. One vendor states this proudly: deep integration into their catalog, they argue, is "far superior to any system that simply reads the data from the outside."
We'd ask every buyer to hear that sentence the way we do. It's an honest description of the design, and a precise description of the boundary. The agent's understanding of your business lives inside one platform's walls, in a world where your business has never lived inside one platform's walls.
WALT made the opposite bet from day one, and our reasoning starts with a claim we keep returning to: data is not software.
In software engineering, code generation was the bottleneck, so agents that generated code transformed the field. In data engineering, generating the transformation was never the hard part. The hard part is everything before it: knowing what the data actually contains, what it should mean, and what good looks like when you're done. That work has a completely different shape, and a completely different cost structure.
Generation vs. impact: The metric that actually matters
Here's the test that cuts through every demo. A CFO never asks, "did the AI write good SQL?" A CFO asks, "is this number correct? Will it be the same number tomorrow? Can I defend it in the board meeting?" Generation is the vendor's metric. Impact is yours.
The platform agents are built, priced, and benchmarked around generation: queries produced, pipelines drafted, tokens consumed. But nobody in your business consumes SQL. They consume answers, and an answer is only valuable if it's right, reproducible, and traceable to governed logic.
That's why WALT serves answers through deterministic inference over a governed data context graph rather than having an LLM improvise new SQL per question: the same question must return the same answer, with lineage attached, every single time. Fluent generation that's 90% right isn't 90% of the value. In finance, in compliance, in anything a decision rides on, it's zero.
What is tokenmaxxing, and why does it inflate agent costs?
Tokenmaxxing is what happens when a pure-LLM agent does data engineering by pushing your data through the model over and over, on a meter, and the bill balloons while the work stalls. Look at the token economics of a coding agent. The input is a prompt and some context: thousands of tokens. The output is code: often more tokens than went in. Generation-heavy and output-dominant.
Data engineering inverts it. Before data engineers write a single line of a transformation, they explore. They profile distributions, chase nulls, check whether customer_id means the same thing in the billing system and the CRM, sample edge cases, validate joins, test assumptions against actual rows.
The input is data measured in billions of rows; the output, after all that work, might be eighty lines of SQL. Massive input, tiny output, the exact opposite of codegen.
Now hand that workload to a generic agent whose only instrument is the LLM, and every act of exploration becomes metered context. To profile a table, it pulls the whole thing into context: hundreds of columns, sampled row by row, through the model. When a query fails, it retries, and re-sends everything it already read. Asked for test data, it generates ten thousand rows token by token–work a three-line script does for free.
Worse, the agent has no opinion about your business, so a human steers it by hand (prompt, inspect, correct, re-prompt) and each replay re-runs that input-heavy exploration.
This is the sledgehammer problem. The big-data era told everyone to capture and store everything, and estates sprawled while the bills compounded. That same advice is now back with a new noun: let the LLM do every step. Exploration, profiling, analysis, testing, generation. It will work in the demo, but the demo has twelve tables.
When nobody knows what good looks like, the meter runs
For most platform-native agents, the company selling you the agent is the same company metering every token it consumes and every query it triggers. The agent's reasoning is billed on the platform's meter. The SQL it executes is billed on the platform's compute. Free allowances are introductory, and the pay-as-you-go meters are already scheduled. An agent that takes ten iterations instead of one is not a problem anyone on the selling side is paid to fix.
The result, for the buyer: tokenmaxxing. You believed you were replacing labor. Instead the labor stayed (someone is still curating, prompting, reviewing) and a consumption line item arrived next to it. This is how migrations and greenfield builds will stall in the agent era: not for lack of capability, but because the token budget ran out at sixty percent complete.
The problems that kill pilots in month two: Value, definition, and identity resolution
There's a class of problems with no keynote demos, because they're invisible until you're live, and then they're everything.
A business user asks: "How did the 6-inch boot do at the downtown store last month?" The database doesn't contain a “6-inch boot” or a “downtown store”. It contains "6 Inch Premium Waterproof" in a product table and "Location 0142" in a store dimension, and nothing in the prompt tells the agent which column either value lives in or how it's spelled.
An LLM guesses here, and a guess returns either an empty result or, far worse, a wrong number that looks right. The same trap repeats one level up: "net sales" means something specific in your company, with exclusions and timing rules that live in nobody's schema. And one level up from that: the same customer exists in four systems under four IDs, and somebody has to decide which one is the truth.
Value resolution, definition resolution, cross-system identity–this is the actual job. WALT’s autonomous data engineers solve it structurally:
1. Value resolution: WALT indexes the values in your data, not just the metadata, so "downtown store" resolves to the real value in the real column before any query is composed.
2. Definition: Canonical definitions live in the Data Context Graph, versioned and governed.
3. Identity resolution: Cross-system identity is mapped across systems as part of building the estate.
No amount of prompting bolts this onto a copilot, because the copilot's context ends where its platform does. And it's exactly where pilots die: month one is the demo, month two is the first wrong answer to the CFO.
Why “centralize-first” is a trap: Fragmentation is the reality
Every one of these agents shares an unstated premise: first, get your data onto our platform, governed by our catalog; then the agent gets smart. It's the most natural premise in the world for a platform vendor. It's also the same project that has been one migration away from being done for a decade at every large enterprise we've ever met.
Fragmentation isn't a transitional state. It's the permanent condition of any company with history: mergers layered on mergers, on-prem next to three clouds, stored procedures next to notebooks, the ERP nobody touches. In the agent era you cannot afford the design pattern of “centralize first, then get agentic productivity”. The sequencing is backwards: the centralization is precisely the multi-year labor you wanted agents to do.
Then there’s the objection every buyer feels in the demo but rarely hears addressed: nobody believes it scales to the whole organization. The curation that makes these agents accurate is per workspace, per domain, per team: scoped tables, written instructions, example queries, benchmarks, an admin.
So "roll it out to the enterprise" doesn't mean flipping a switch; it means redoing that setup for finance, then supply chain, then marketing, then the subsidiary you acquired in 2019, each with its own definitions and its own mess. The work scales linearly with your org chart, and the people who must do it are the same scarce engineers you started with. That's why these pilots impress in month one and quietly stall by quarter two. The org-scale problem isn't solved by a better copilot, but by an engineer that does the curation itself.
Heterogeneity has to be embraced, not awaited. That demands data engineering agents that are stack-agnostic and topology-agnostic: agents that treat your fragmented estate as the starting condition, work with the tools you've already invested in or with open source, and build value on whatever topology you actually have. It's also the only position that survives the future: platforms will keep evolving, and an agent married to one of them ages with it. An agent loyal to your estate compounds with you instead.
What does a truly autonomous data engineer look like? 4 tests to consider
So what should buyers hold out for? We'd offer four tests.
1. Virtually zero prompt.
A true autonomous data engineer should not wait to be prompted table by table. It should index your fragmented estate, study your sources, and observe your consumption patterns: what is actually queried, by whom, for what decisions. Then it should get to work.
This is how WALT's crew operates:
- The Ingestor discovers and lands data from the sources where the real mess lives;
- The Transformer shapes it into canonical models driven by real consumption;
- The Reasoner builds the Data Context Graph and serves deterministic answers;
- The Operator watches for drift and fixes issues before anyone notices;
- The Governor enforces policy as the estate evolves.
The prompt, to the extent there is one, is your estate itself.
2. Has an opinion about what good looks like.
An agent that arrives with no point of view outsources the point of view to your staff, one iteration at a time, and we've covered what those iterations cost.
WALT's agents are opinionated by design: trained on dozens of world-class medallion repositories, built by teams who have run world-class data platforms, arriving with positions on grain, conformance, naming, layering, and quality gates. You correct an opinionated agent occasionally; you babysit an unopinionated one forever.
3. Fixes itself autonomously.
Pipelines break. Schemas drift. Sources go dark at 2 A.M. The question is what happens next: does the agent diagnose the failure, trace the root cause, and propose or ship the fix, or does it hand you a stack trace and wait to be prompted again?
"Try again" is not an operations strategy. WALT's Operator watches for drift, diagnoses breakage, repairs what it can autonomously, and arrives with the root cause and recommended fix when a human should decide. An agent that can't explain its own failures hasn't replaced an engineer; it has recruited you as one.
4. A neuro-symbolic architecture, because the token math demands it.
The work that dominates data engineering (exploration, profiling, validation, testing) is exactly the work a deterministic engine does for fractions of a cent, at full fidelity, across billions of rows. WALT uses the LLM where neural strengths are real: understanding intent, resolving ambiguity, classifying. The heavy lifting (profiling, inference over the context graph, SQL composition, verification) runs on deterministic systems.
The LLM is mostly a classifier, not a forklift. That discipline isn't an optimization; it's the only architecture under which autonomous data engineering is economically possible at enterprise scale. It's also why WALT's costs don't scale with your row count.
Platform-native agents vs. autonomous data engineers: Comparison table
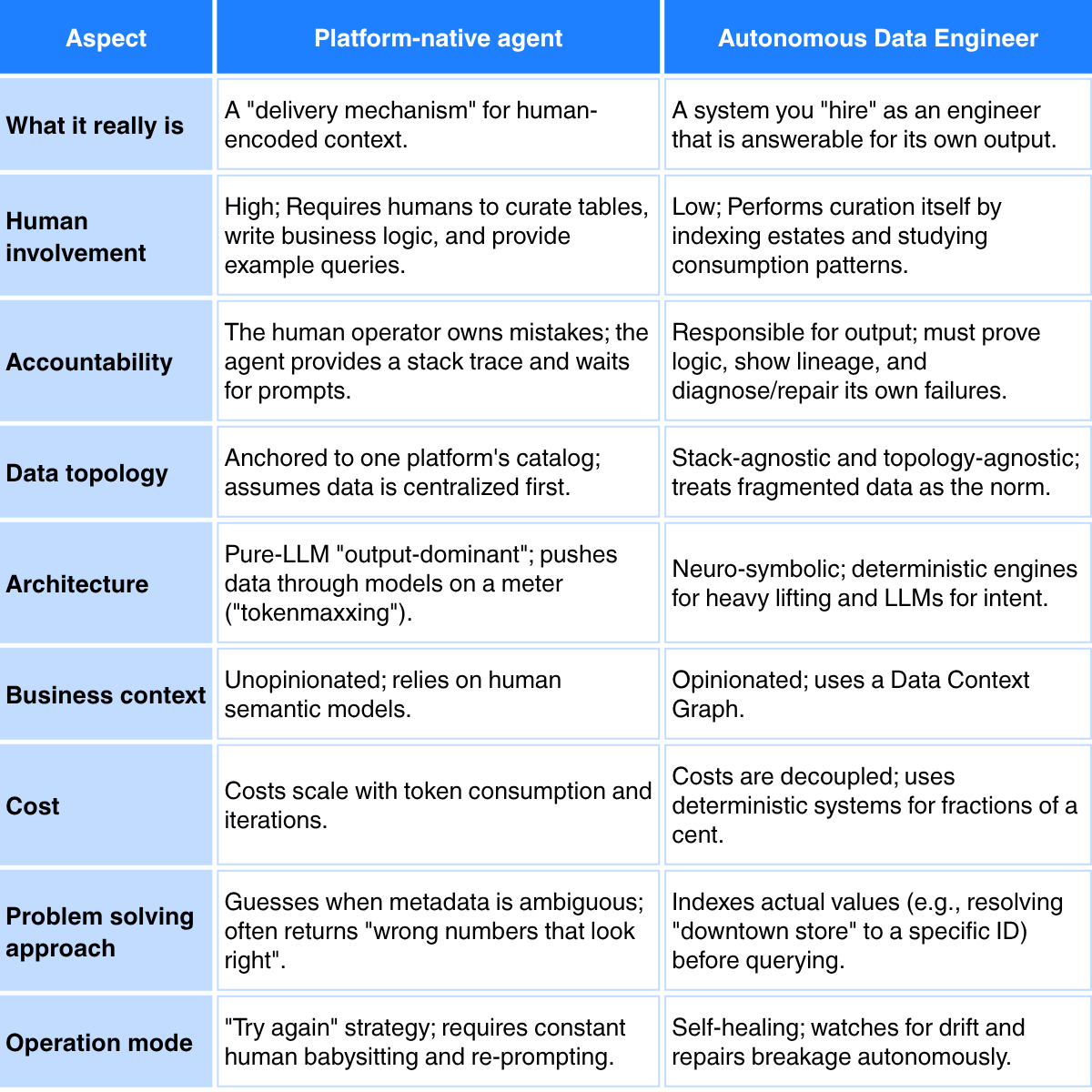
Bottom line: Keep your platform. Question the agent.
Let's be clear about what we are not saying. We are not telling anyone to leave their platform. The modern platforms are superb infrastructure, and WALT works on them, with them, every day. Your warehouse stays, your BI tools stay, your investments stay. The platforms aren't the issue.
The issue is an assumption that buyers are being handed along with their renewal: that the agent should come from the platform too.
Nobody believes their IDE vendor should be their software engineer. The same logic holds here. Your platform should be the best possible infrastructure for your data. Your data engineer, human or autonomous, should work for you: across every system you own, opinionated about your business, architecturally uninterested in maximizing your consumption.
That's the line we'd encourage every buyer to draw this week, somewhere between the keynote and the booth: the platform and the engineer are different purchases. Choose each one on its own merits, and ask, of any agent you're shown, the two questions that matter: who does it work for, and who answers when it's wrong?



Meet WALT, your next Data Engineer that builds and runs your entire data platform
.webp)

.webp)